
第1步:打印为图像文件
使用Adobe Reader打开相关的PDF文档,从“文件”菜单下执行“打印”命令,此时会弹出“打印”对话框,由于一般情况默认的打印机大多为真实的物理打印机而非虚拟打印机,因此请从“打印机”下拉列表框中选择“Microsoft Office Document Imaging Writer”,然后单击“确认”按钮,确认后即可将PDF文档输出为TIFF格式的图像文件,如图1。
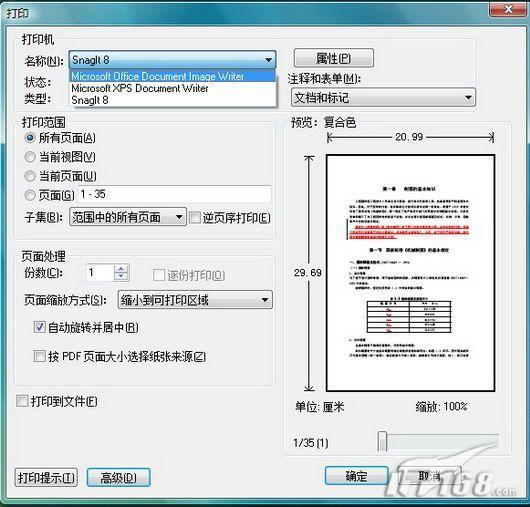
图1 打印文档 第2步:读取图像文件
运行Microsoft Office Document Imaging,这个组件可以从Office程序组的“Office工具”子程序组下找到,打开刚才所打印的图像文件,选择“工具→将文本发送到 Word”的命令,此时会弹出图2所示对话框,如果你不需要更改输出文件夹,那么直接单击“确定”按钮,此时会提示“必须在执行此操作前重新运行OCR。 这可能需要一些时间”,确认后即可开始转换操作。
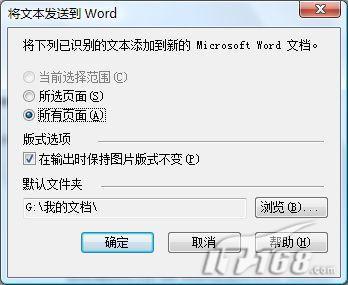
图2 将文本发送到Word 稍等片刻,转换完成后,系统会自动打开Word窗口并显示从PDF文档转换而来的文档内容(见图3),不过如果PDF文档比较复杂的话,某些内容例如图像、表格可能显示的不太完美。
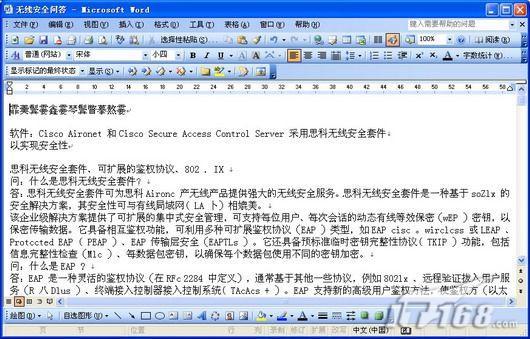
图3 PDF文档转换而来的文档内容 如果你只是需要获得PDF文档中的文字内容,那么操作是非常简单的,首先使用Adobe Reader打开相关的PDF文档,然后从“文件”菜单下执行“另存为文本”的命令,在随之弹出的对话框中指定保存路径和文件名,确认后需要稍等片刻,保 存时间取决于当前文档的页码),我们很快就可以获得一份完整的文本文件,至于原文档中的图像内容,就只能另想它法了
