这篇文章主要想描述一下该怎样以一种安全和可伸缩性的方式使得程序并行化。在多核的今天,我们可能更加需要思考如何编写一个良好的并行程序。文中有相当的内容来自《Intel Threading Building Blocks》,虽说它针对 C 讲解,但原理通用,在跟语言,平台有关联的时候,楼主会使用 .NET 阐述。
每个软件开发人员都不得不面对并行编程。以前以及现在,我们在完成任务时,首先会考虑选择最佳算法,实现语言等。但现在我们必须首先考虑任务的内在并行性。而这反过来又会影响我们对算法和实现的抉择。如果试着在最后考虑并行,还不如不要思考并行。程序也不能很好的工作。
现实中,我们每天都在并行思考。举两个例子:
我们对并行并不陌生。实际上,并行是相当自然的思维方式。只是似乎开发人员并不常用这种方式。一旦关注并且使用并行编程,那我们便会思考并行。那时我们将会首先思考整个项目的并行性,然后才考虑如何进行编码。
应该怎样来实现程序并行呢?本文将讲述一种重要的思维方式:并行分解。
应用程序有多种并行方式,下面将分别描述。
数据并行
如图1所示,它是一种很典型的数据并行示例:拥有大量的数据,并且这些数据都采取同一种操作来转换每一块数据。
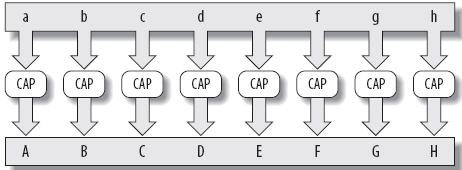 图1
图1
图1表示,把数据集中的每一个英文小写字母均转换成相对应的英文大写字母。这个很简单的示例向我们展示了要操作的数据集和同时应用于每个元素的转换操作。那些为超级计算机编码的开发人员最喜欢碰到这种问题,因为要使其并行化实在简单。
任务并行
数据并行往往最终受限于你要处理的数据量。现实中,CPU 拥有多少核心数也无法应付巨大的数据增长,即使 CPU 可以乱序并行执行多个指令。而且很多时候瓶颈并不在 CPU 处,内存,缓存也有着重要的影响,甚至我们可以让 GPU 来参与处理。这时,我们就要转向任务并行了(如图2)。
任务并行意味着拥有大量不同的,独立的,由共享数据联系起来的任务。图2表示在相同的数据集上应用一些数学运算规则来获取其值,而这些值都相对独立。换句话说,我们可以单独计算其值,而不受其他计算的影响。
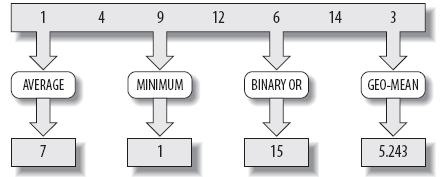 图2
图2
管道/流水线(合并数据和任务并行)
发现纯粹的任务并行要比纯粹的数据并行难的多。很多时候,当你发现任务并行时,它同时也是一种特定的管道/流水线。许多独立的任务需要应用到数据流上。每一项都会被阶段性处理,正如图3中从 a 到 A 所展示的那样。
 图3
图3
假如使用管道/流水线,数据流 A 可以被处理的更快速。因为不同项的不同阶段可以并行处理。管道/流水线比其他处理方式更高级:它可以更改数据或者针对选定的项跳过某些步骤。汽车工厂的装配线就是一个管道/流水线的良好示例。如图4:
 图4
图4
混合方案
考虑下在信纸上写完你的浓浓情思之后,该如何寄信。大概需要六个步骤:折叠信纸、把信纸装入信封、密封封口、在信封正面写上地址、贴上邮票、投递。如果现在你有六个人来完成大量的信封装填投递任务,你会如何安排?很自然的反应是按照上述六个步骤,每个阶段安排一人来完成它。如图5所示:
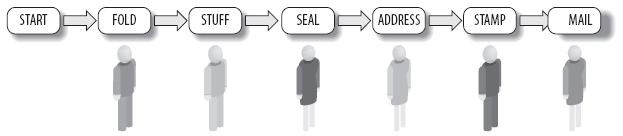 图5
图5
参照前面所讲的数据并行,你或许应该把这六个人单独分开,每个人独自来完成所有步骤。如图6所示:
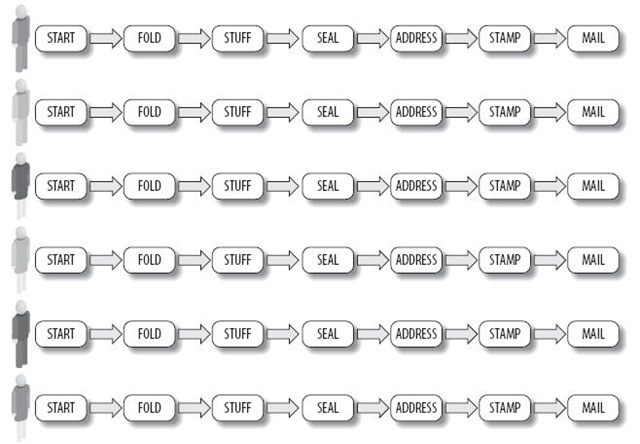 图6
图6
如果每个人在不同的位置工作,并且彼此相隔甚远,那么图6很显然是个正确的选择。这就是所谓的“粗粒度并行”,因为彼此任务互动很少(他们只不过取走信封时会在一起,然后转身就去做工作了,甚至包括投递)。此外,如图5所示的是“细粒度并行”,这是因为他们时常交互(每一个信封都会由上一个人传过来,然后再传给下一个人)。
程序不可能完全符合现实,但有时候足够接近也很有用。在这个示例中,或许第四个步骤(在信封正面写上地址)会让三个人保持足够忙碌,但前两个步骤和后两个步骤仅仅需要一个人就可以赶上了。图7表明了每个步骤的工作量,而图8则说明了一个真正的数据并行和任务并行的混合方案。
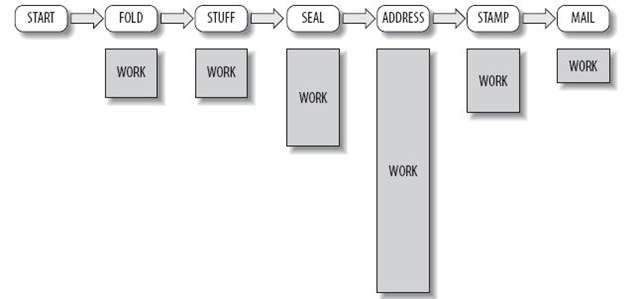 图7
图7
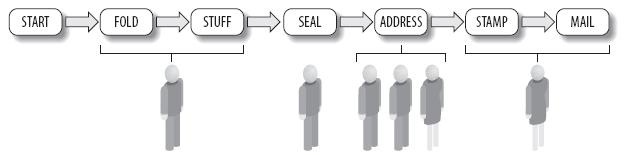 图8
图8
实现并行
上述示例可以用下面两个步骤来简单的表达:
那我们应该如何并行编程?首先,思考你的程序哪些地方可以并行。其次,根据实际情况进行并行分解。如果幸运的话,我们可能只碰到数据并行,这个就很简单了。比如并行迭代。当碰到复杂的情况时,依据上述分类来逐一比对,最麻烦也不过是混合方案而已。请尽可能使用硬件并行,这会大大消除使用锁机制同步的需要,而且也高效的多。
|
||||||||||||||||||||
 |
|
| 题目筛选器 | ||||||||||||||||||
|
||||||||||||||||||
|
|
|
|
|
|
|
