微信朋友圈广告的事儿过去几天了,眼看各路大神一波一波的评述事件,在揣摩数篇大作后,有两个问题值得探讨一下。
第一个疑问:拥有了很多的数据,就是大数据了么?
微信拥有11亿以上用户,4亿多活跃用户,每天产生的数据量是天文数字,这些自由发布,没有导向的社交软件产生的数据,在这次朋友圈广告中到底用来干嘛了呢?
以这次的广告商在朋友圈里的发布,用几种常见的大数据应用方式,王旭亮老师来为大家揣测一下:
模式一:
这个模式使用的是微信用户的海量数据,筛选出与广告商的定位一致的群体,例如用肾的,例如关注奢侈品、名车的,用各种标签条件定义用户,进而推送广告。
模式二: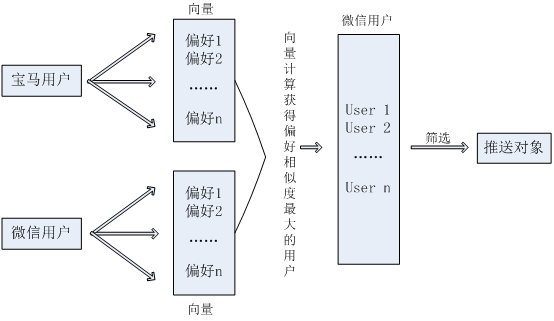
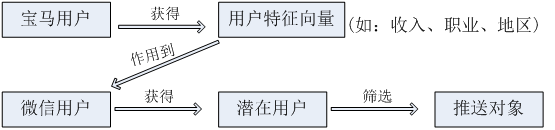
利用微信各种用户数据勾勒出属性,如用户的收入,年龄,区域,教育水平,所处行业这类基本特征,比对广告商的产品定位人群属性,以属性相近的部分,加上事先做推广测试时候的用户反馈参数,如预告时右上角的是否感兴趣选项,再筛选出来的群体,进而推送目标。
模式三:
当属性不全的时候,就要应用第三种模式,以用户的偏好为分类条件,如曾发布喜欢旅游,喜欢科技产品,喜欢吃喝玩乐等等,就成为了定义条件。以这些偏好进行排序,筛选出前20最受用户关注的偏好,再以这些偏好跟广告商的客户定位进行比对,以相似度最高的部分为推送人群。
上述三种常见的大数据推荐模式并不涉及到社交属性。其实,如果精准分析能够到用户消费行为和倾向这个层级,社交属性是可以弱化的,因为后者的实质作用是扩大受众群体而已。
以微信的用户体量,精准分析出几百万甚至上千万的宝马潜在用户应该不是难事,但这次推送并不是一对一推到用户的对话框,而是在朋友圈利用社交属性来进行传播,那还是Feed流广告的路子,并没有将大数据的精准能力应用到位。因此,微信拥有海量数据不假,但微信是不是在做大数据分析要看在海量数据上做什么。这次推送并不是严格意义上的大数据行为。
第二个疑问:这次的广告效应,几乎是以事件炒作,利用用户的转发而形成的,那么跟大数据有什么关系呢?
产生这个疑问,就是因为这次三家广告商,都投放的是品牌广告,并不是具体产品的宣传,提高的是品牌的认知度。王旭亮老师认为在微信的用户体量下,加上“高中低废”的人群分类话题炒作,应该归入事件营销的路子上,没看出来跟大数据应用有什么关联,因为最终消费转化还是靠广告商的自我努力。
有这么多用户数据为什么不利用呢?我们大胆的再假设一下:
1、微信对它的11亿多用户并不全了解,否则它应该把11亿用户里面哪些是真土豪、真屌丝找到,相应地推宝马或者可乐,精准跟事件营销又不是冲突的。
2、微信从“高质种子用户”开始做设定,隐含的前提是:活跃度高和参与广告互动的用户以及他们的社交脉络跟宝马、vivo和可口可乐的广告受众有相当的重合度。这个设定显然从一开始就准备从事件炒作角度进行,并没有以精准为根本。
那么不难看出微信是以社交属性为广告推荐的根本,并没有应用基于内容、协同过滤、规则、效用、知识上的大数据能力,关注的并不是人和物之间的强相关性(例如偏好、购买、意图等)。
从这两个疑问能推导出来的结果,我们发现,这是一次成功的事件炒作,是一次PR事件,是一次传播效应的验证,压根没有大数据什么事儿。
那么真正的大数据推荐到底是什么呢?
从数据库里面找到某个微信用户的所有朋友,这跟大数据没什么关系,大数据的一个重要特征是分析不同来源、不同性质的数据信息。例如,把微信用户信息和宝马用户信息合在一起分析,这才是典型的大数据应用场景。专业上,这是大数据的多样性属性(Variety)。
而大数据推荐的目的是发现表面上可能不相关、实质上相关的两个实体。这样的隐含关系在小数据范围内都不容易,在大数据的情况下难度可想而知。我们把这个问题拆成几个步骤来说明:
第一步,要解决“什么样数据可以被纳入分析?”因为数据量太大,把无关的东西纳入进来,不但会增加无谓的计算量,也会产生很多干扰。因此,去噪(noise reduction)是第一步。以微信这次的朋友圈广告商宝马汽车的例子说明:
如果某个微信用户声称自己昨天买了宝马,但宝马的购车用户列表里没这个人,那么这个用户该不该被剔除将会影响接下来的步骤。
第二步,定基准数据(benchmarking)。我们要分析两个实体相关与否,关键是看它们的相似度。有的人说,80%的相似就可以了,有的说超过50%就OK。那么该怎么定这个相似度呢?交由专家判断是一个方法,交由统计结果判断是另一个方法,最好的方法是大数据模型能够自我学习去判断这个基准。
第三步,数据降维(dimension reduction)。所谓降维,就是把不需要考虑或者不重要的因素从推荐系统中去掉,从大数据到小数据。例如,微信用户跟宝马用户之间可能存在很多的相关点(电话号码、城市、年龄、土豪级别、付款记录等),不是所有的相关点都对推荐有用的。比如,富二代18岁就开宝马了,普通人可能要30岁才能开上,因此年龄可能并不是分析的关键。
总之,降维的根本目的是为了计算方便,规避天文数字的数据分析,至于如何降维和降维的算法,容以后细说。
第四步,选择合适的推荐算法。上文提到的推荐算法是应用最广的,也各有优缺点。选择哪种算法,要考虑解决怎样的问题、数据量大小、特征选择等因素。也就是要将人事物的背后关联,用数据的方式联系起来。
第五步,大数据推荐在很多情况下要考虑实时推荐的问题。例如,一个新用户进来,你要推给他宝马、vivo还是可口可乐。这个涉及推荐相同的效率以及该用户的信息,大数据框架的设计必须足够完整。
此外,大数据推荐的结果,通常也被称为“大数据预测”,应用场景从足彩到股票,不一而足。能够做好大数据预测的公司,才是真正的大拿。
据以上推论,大数据下的推荐系统并不简单等同于社交关系的推导,必须是基于更为严格的需求分析和更复杂的系统设计。微信拥有天然的条件(巨量数据、资金、团队等),但在这次广告推送中,表现出来的大数据应用并不到位,虽然说用了大数据能力,但更像“大数据是个筐,什么都可以往里装”的包装手法,实在是可惜。
|
||||||||||||||||||||
 |
|
| 题目筛选器 | ||||||||||||||||||
|
||||||||||||||||||
|
|
|
|
|
|
|
